
티스토리 뷰
[#5 Apache Kafka 구축] Spring boot 기반 마이크로서비스 아키텍처(Microservices Architecture, MSA)
Mr.spock 2021. 3. 31. 08:21
#5 Apache Kafka 구축
Apache Kafka
Apache Kafka: A Distributed Streaming Platform.
kafka.apache.org
MSA를 하다 보면 트랜잭션이나, 서비스 간의 통신 부분에서 많은 어려움을 겪는다. 예전에 아무것도 모를 때에는 당연한 듯 서비스 간에 REST API로 호출한다고 생각했는데, 그렇게 하다 보니 많은 문제점이 생겼었다.
그런데 그러한 문제를 해결해 주는 것이 Apache Kafka다 Kafka는 링크드인에서 처음 개발된 분산 메세징 시스템이다. 토픽(Topic)을 기준으로 발행(Publish)과 구독(Subscribe) 형태의 모델로 되어 있다.
데이터를 만들어내는 프로듀서(Producer, 생산자), 소비하는 컨슈머(Consumer, 소비자) 둘 사이에서 중재자 역할을 하는 중개인(Broker)으로 구성된 느슨한 결합(Loosely Coupled)의 시스템이다.
상세한 설명에 대해서는 또 친절하게 설명을 잘해주신 분이 계셔서 해당 블로그의 링크를 걸도록 하겠다.
[Kafka] #1 - 아파치 카프카(Apache Kafka)란 무엇인가?
데이터 파이프라인(Data Pipeline)을 구축할 때 가장 많이 고려되는 시스템 중 하나가 '카프카(Kafka)' 일 것이다. 아파치 카프카(Apache Kafka)는 링크드인(LinkedIn)에서 처음 개발된 분산 메시징 시스템이
soft.plusblog.co.kr
이번 #0~#5번의 포스팅은 실제 구축에 대한 내용 위주로 담으려 했기 때문에 자세한 설명이나 개념을 잡기 위해서는 다른 좋은 글들이 많으니, 양해 바란다.
- Zookeeper 설치 및 실행
kafka를 설치하기 위해서는 Zookeeper를 설치 및 실행해야 한다. 아래의 사이트로 방문하여 다운로드한다.
www.apache.org/dyn/closer.cgi/zookeeper/
Apache Download Mirrors
Copyright © 2019 The Apache Software Foundation, Licensed under the Apache License, Version 2.0. Apache and the Apache feather logo are trademarks of The Apache Software Foundation.
www.apache.org
웹 사이트에 방문해서 HTTP 아래의 주소를 클릭한다.

버전 중 일단 높은걸 받았다.

무슨 파일을 받을까 하다가 apache-zookeeper-3.7.0.tar.gz를 받아서 했는데 안되더라, 그래서 찾아보니 -bin이 붙은걸 받아서 하라고 하길래 해당 파일을 받아서 했더니 정상 동작하였다.
원하는 위치에 압축을 풀고 해당 폴더 내에 data폴더를 생성해준다.

conf폴더 안에 있는 zoo_sample.cfg를 복붙 해서 zoo.cfg로 이름을 변경해준다.
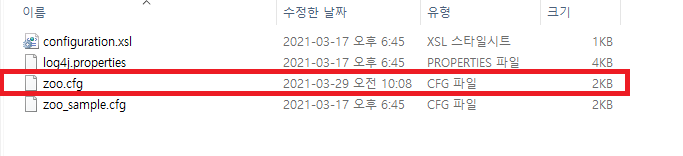
zoo.cfg파일을 오픈해서 dataDir위치를 아래와 같이 설정해준다.
dataDir=D:\\workspace\\apache-zookeeper-3.7.0-bin\\data
zookeeper를 실행해보자 cmd창을 열어 해당 폴더로 이동 한 뒤 zkServer.cmd를 입력 및 실행한다.

대략 아래와 같은 상태가 되면 실행이 된 상태다
일단 실행해둔 채 Kafaka설치 및 실행해보자
- Apache Kafaka 설치
설치를 위해 아래의 사이트로 방문하여 다운로드한다.
Apache Kafka
Apache Kafka: A Distributed Streaming Platform.
kafka.apache.org

원하는 위치에 압축을 풀고 \kafka_2.13-2.7.0\config 폴더의 server.properties를 파일 텍스트 편집기로 오픈하여 log.dirs를 설치경로로 변경한다.
log.dirs=D:\\workspace\\kafka_2.13-2.7.0\\logskafka를 실행해보자 cmd창을 열어 해당 폴더로 이동 한 뒤 아래와 같이 입력 및 실행한다.
bin\windows\kafka-server-start.bat config\server.properties
뭔가 로그가 아래처럼 한 가득 나오고 대부분의 로그가 [INFO]로 나오는 걸 보니 잘 된 것 같아 보인다.
그래도 정말 잘 실행되었는지 확인을 해 볼 필요가 있으니 cmd창을 하나 더 열어서 kafka설치 경로로 이동해서 아래의 테스트를 해보자
[토픽 생성] 설치경로에서 아래처럼 명령어를 통해 토픽을 생성한다.
bin\windows\kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic topicMakeTest
위의 캡처 화면과 같이 "Created topic topicMakeTest"라고 나타나면 정상적으로 생성된 것이다.
[토픽 리스트 조회] 설치경로에서 아래처럼 명령어를 통해 토픽 리스트를 조회한다.
bin\windows\kafka-topics.bat --list --zookeeper localhost:2181
[Kafka 컨슈머 시작] 설치경로에서 아래처럼 명령어를 통해 컨슈머를 시작한다.
bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic topicMakeTest아무 변화가 없는 것이 정상이다. 컨슈머는 구독자이기 때문에 토픽을 통해 메시지가 오기를 기다리고 있다고 보면 된다.
이제 토픽을 발행할 프로듀서를 시작해보자 또 다른 cmd창을 열어주고 설치경로로 이동해서 아래의 명령어를 통해 프로듀서를 실행해보자
bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic topicMakeTest
위와 같이 메시지를 입력할 수 있는 상태가 된다. 그럼 바로 위에서 실행해둔 컨슈머 창과 프로듀서 창을 나란히 띄워두고 프로듀서에서 메시지를 입력해보자 아무 메시지나 관계없다.
나는 프로듀서에서 창에서 "this is a message"라고 topicMakeTest라는 토픽에 메시지를 전달해 보았다.

아까 띄워둔 컨슈머 창에서 메시지를 받은 것을 아래와 같이 확인할 수 있다.
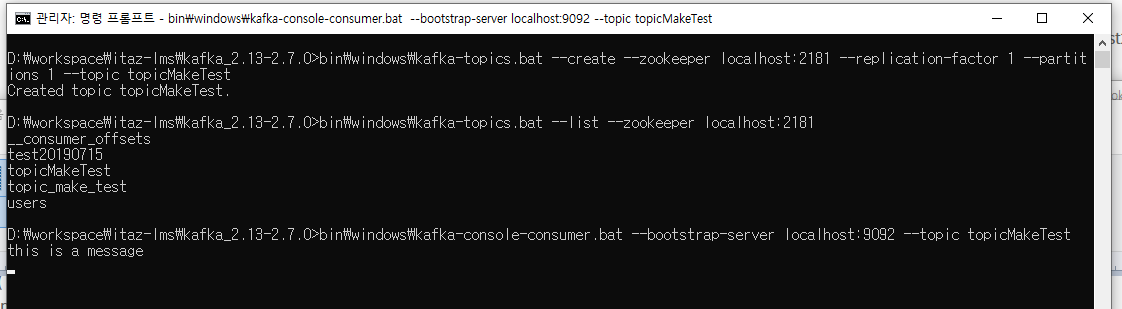
이렇게 메시지를 발행하고 구독할 수 있는 것을 확인해 보았다. 이제 Spring boot프로젝트에 kafka를 적용할 차례다.
프로젝트를 별도 새로 생성하진 않고 앞에 있었던 프로젝트의 application.yml파일에 아래와 같이 kafka관련 설정을 추가해준다.
# kafka
spring:
application:
name: MS2
kafka:
# cluster구성 시 아래와 같이 콤마로 표현
bootstrap-servers: localhost:9092,localhost:9093,localhost:9094
consumer:
group-id: group_id_ms2
auto-offset-reset: earliest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
producer:
retries: 0
acks: all
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
그리고 테스트를 위해 Consumer.java, Producer.java, KafkaController.java 파일을 생성해 아래와 같이 예제 코드를 작성해준다.
Consumer.java
import java.io.IOException;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Service;
@Service
public class Consumer {
private final Logger logger = LoggerFactory.getLogger(Producer.class);
@KafkaListener(topics = "users", groupId = "group_id_ms2")
public void consume(String message) throws IOException {
logger.info(String.format("#### -> Consumed message -> %s", message));
}
}Producer.java
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Service;
@Service
public class Producer {
private static final Logger logger = LoggerFactory.getLogger(Producer.class);
private static final String TOPIC = "users";
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
public void sendMessage(String message) {
logger.info(String.format("#### -> Producing message -> %s", message));
this.kafkaTemplate.send(TOPIC, message);
}
}KafkaController.java
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping(value = "/kafka")
public class KafkaController {
private final Producer producer;
@Autowired
KafkaController(Producer producer) {
this.producer = producer;
}
@PostMapping(value = "/publish")
public void sendMessageToKafkaTopic(@RequestParam("message") String message) {
this.producer.sendMessage(message);
}
}위와 같이 작성하고 프로젝트를 실행(F5)한다.
컨트롤러에 작성된 publish를 통해서 아래와 같이 토픽을 발행해 보자
curl -X POST -F "message=test message" http://localhost:80/kafka/publish아래는 메시지를 보냈을 때 ms2 서비스의 로그를 발췌해 보았다.
2021-03-30 17:44:47.054 INFO 24688 --- [p-nio-80-exec-1] o.s.web.servlet.DispatcherServlet : Initializing Servlet 'dispatcherServlet'
2021-03-30 17:44:47.060 INFO 24688 --- [p-nio-80-exec-1] o.s.web.servlet.DispatcherServlet : Completed initialization in 6 ms
2021-03-30 17:44:47.097 INFO 24688 --- [p-nio-80-exec-1] kr.itaz.lms.ms2.Producer : #### -> Producing message -> test message
2021-03-30 17:44:47.101 INFO 24688 --- [p-nio-80-exec-1] o.a.k.clients.producer.ProducerConfig : ProducerConfig values:
acks = 1
batch.size = 16384
bootstrap.servers = [localhost:9092]
buffer.memory = 33554432
client.dns.lookup = default
client.id = producer-1
compression.type = none
connections.max.idle.ms = 540000
delivery.timeout.ms = 120000
enable.idempotence = false
interceptor.classes = []
key.serializer = class org.apache.kafka.common.serialization.StringSerializer
linger.ms = 0
max.block.ms = 60000
max.in.flight.requests.per.connection = 5
max.request.size = 1048576
metadata.max.age.ms = 300000
metadata.max.idle.ms = 300000
metric.reporters = []
metrics.num.samples = 2
metrics.recording.level = INFO
metrics.sample.window.ms = 30000
partitioner.class = class org.apache.kafka.clients.producer.internals.DefaultPartitioner
receive.buffer.bytes = 32768
reconnect.backoff.max.ms = 1000
reconnect.backoff.ms = 50
request.timeout.ms = 30000
retries = 2147483647
retry.backoff.ms = 100
sasl.client.callback.handler.class = null
sasl.jaas.config = null
sasl.kerberos.kinit.cmd = /usr/bin/kinit
sasl.kerberos.min.time.before.relogin = 60000
sasl.kerberos.service.name = null
sasl.kerberos.ticket.renew.jitter = 0.05
sasl.kerberos.ticket.renew.window.factor = 0.8
sasl.login.callback.handler.class = null
sasl.login.class = null
sasl.login.refresh.buffer.seconds = 300
sasl.login.refresh.min.period.seconds = 60
sasl.login.refresh.window.factor = 0.8
sasl.login.refresh.window.jitter = 0.05
sasl.mechanism = GSSAPI
security.protocol = PLAINTEXT
security.providers = null
send.buffer.bytes = 131072
ssl.cipher.suites = null
ssl.enabled.protocols = [TLSv1.2]
ssl.endpoint.identification.algorithm = https
ssl.key.password = null
ssl.keymanager.algorithm = SunX509
ssl.keystore.location = null
ssl.keystore.password = null
ssl.keystore.type = JKS
ssl.protocol = TLSv1.2
ssl.provider = null
ssl.secure.random.implementation = null
ssl.trustmanager.algorithm = PKIX
ssl.truststore.location = null
ssl.truststore.password = null
ssl.truststore.type = JKS
transaction.timeout.ms = 60000
transactional.id = null
value.serializer = class org.apache.kafka.common.serialization.StringSerializer
2021-03-30 17:44:47.122 INFO 24688 --- [p-nio-80-exec-1] o.a.kafka.common.utils.AppInfoParser : Kafka version: 2.5.1
2021-03-30 17:44:47.123 INFO 24688 --- [p-nio-80-exec-1] o.a.kafka.common.utils.AppInfoParser : Kafka commitId: 0efa8fb0f4c73d92
2021-03-30 17:44:47.123 INFO 24688 --- [p-nio-80-exec-1] o.a.kafka.common.utils.AppInfoParser : Kafka startTimeMs: 1617093887122
2021-03-30 17:44:47.127 INFO 24688 --- [ad | producer-1] org.apache.kafka.clients.Metadata : [Producer clientId=producer-1] Cluster ID: w55DwGQnQVCwYmOdAneDxg
2021-03-30 17:44:47.162 INFO 24688 --- [ntainer#0-0-C-1] kr.itaz.lms.ms2.Consumer : #### -> Consumed message -> test message
#### -> Producing message -> test message
프로듀서를 통해 "test message"라는 message가 발행되었고. config 정보가 로그로 나타나며
#### -> Consumed message -> test message
위와 같이 컨슈머에서 "test message"를 받았다고 나타난다.
지금은 하나의 서비스에서 메시지를 보내고 받아서 크게 의미가 없어 보일 수 있으나, 다른 서비스를 만들어서 해당 서비스에서는 컨슈머만 만들고 토픽에 대해 구독만 해두면, 해당 서버에서도 동일하게 메시지를 받을 수 있다는 것을 한번 테스트 해보길 권장한다.
그래서 메시지를 보내고 받으면 이게 뭐? 어디서 쓸 수 있는 건데 라고 생각할 수 있을 것이다. 설명을 하려면 EDA(Event-Driven-Architecture)에 대해서 한 번 시간이 되면 읽어보길 바란다.
jaehun2841.github.io/2019/06/23/2019-06-23-event-driven-architecture/#event-driven-%EB% 9E%80
Event-Driven-Architecture란? | Carrey`s 기술블로그
Event Driven 란? Event Driven은 IT 영역에서 오래 사용된 키워드이며, 현재도 그 영향력이 대단하여 2018년 Gartner에서 선정한 유망한 기술 트렌드 중 하나로 뽑히기도 했다. (Top 10 Strategic Technology Trends fo
jaehun2841.github.io
언젠가 어느 부분에 MSA로 시스템을 구성할 경우 트랜잭션이나 서비스 간의 통신에 대한 어려움에 대해 얘기한 적이 있는데 그런 부분을 어느 정도 해결해 줄 수 있는 것에 대한 내용이다. 결과적으로는 Event를 통해 데이터의 최종적인 일관성을 유지함에 의미가 있다.
예를 들어 쇼핑몰을 MSA로 구축 시 주문, 결제, 배송 시스템을 각 서비스로 나누었을 때 아래와 같이 활용될 수 있다.
- 사용자는 물건을 보고 배송정보를 입력하고 원하는 결제 방식으로 결제를 할 것이다. 그러면 결제 서비스에서는 사용자의 결제 내역을 저장하고 Kafka의 /payment라는 토픽에 결제 내역에 대한 정보를 담아서 메시지를 발행한다.
- 주문 서비스에서는 /payment라는 토픽을 구독하고 있다가 해당 토픽을 통해 이벤트가 발생할 경우(메세지가 올 경우) 해당 메시지에 담긴 정보를 가지고 결제가 된 건지, 취소가 된 건지 등을 내용을 확인해서 주문내역에 입력을 하고 /order 라는 토픽에 주문 내역에 대한 정보를 담아서 메세지를 발행한다.
- 배송 서비스는 /order라는 토픽을 구독 하고 있다가 이벤트가 발생 할 경우 해당 메세지에 담긴 주문 정보를 가지고 배송에 관련된 처리를 한다.
이와 같이 활용될 수 있고 3번 상황에서 배송하려는 물품의 재고가 없을 때에는 아래와 같이 처리가 된다.
- 배송 서비스에서는 /delivery라는 토픽을 통해 해당 주문건에 대한 "재고 없음"에 대한 내용을 담아 메시지를 발행한다.
- 주문 서비스에서는 /delivery라는 토픽을 구독하고 있다가. 재고 없음에 대한 메시지를 받아 해당 정보에 기반한 주문 처리 로직을 수행하고 /order 토픽에 주문취소 메세지를 발행한다.
- 결제 서비스에서는 /order 토픽을 구독하고 있다가 주문취소 메세지를 구독하여 해당 건에 대한 결제 취소 로직을 수행하고, 사용자에게 재고 없음으로 주문이 취소되고, 결제한 금액은 정상적으로 취소하여 언제 까지 환불된다는 내용을 리턴한다.
위와 같이 실제로 각 서비스에서 수행할 업무에 대한 데이터는 저장소에 다 입력이 되지만, 재고 없음, 취소 등의 다양한 상황에 맞는 이벤트 기반의 설계를 구축해 둠으로써 최종적으로 결제는 취소되고, 주문내역도 취소로 처리되고 하는 등의 최종적인 일관성을 유지할 수 있다.
이와 같이 시스템이 운영되기 위해서는 도메인 기반의 설계와 프로그램 코딩에 대한 이해가 필요하며, 처음 하게 되면 많은 시행착오를 거쳐야 될 것이라 판단된다.
그래서 MSA에서는 이런 서비스들 간에 이벤트 기반에 처리되어야 할 일이 최대한 없도록 서비스를 나누는 것이 매우 중요하며 이러한 상황이 생기지 않도록 하는 것이 가장 좋다고 생각이 된다.
이후 언제 작성할지 모르겠지만, 실제 전체적인 시스템을 구축해 나가며 겪은 시행착오와 결과물에 대한 글을 작성할 것인데 그때가 언제가 될지는 잘 모르겠다.
'development' 카테고리의 다른 글
- Total
- Today
- Yesterday
- slueth
- ADL-LRS
- 목탄
- 신세계 아카데미
- 트랜잭션 추적
- zookeeper 클러스터
- spring boot
- 그림 그리기
- windows환경
- 초보
- Python
- Kafka
- zookeeper
- 취미생활
- axios
- MSA
- 프레임워크
- 카프카클러스터
- 풍경그림
- Eclipse
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |